New Reading page, powered by the Airtable API
In all my years as an absolute book fiend with a personal website, I’ve never hosted my reading list here! That’s now changed with a Reading page, the start of a new /is/ section of my site.
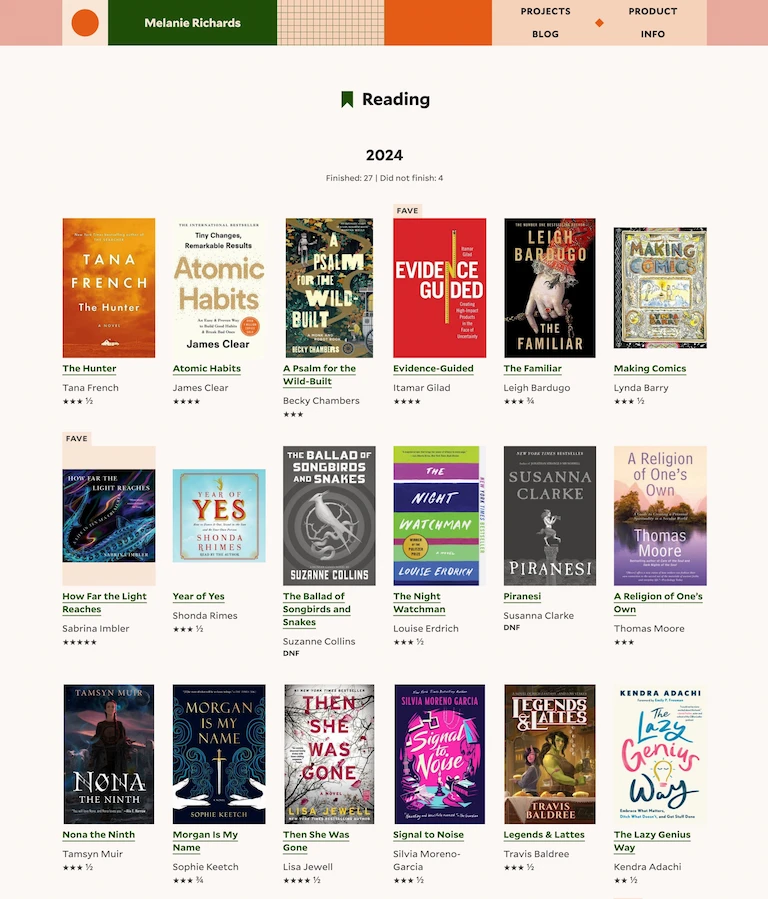
This site is built with the Eleventy SSG, and I’m using the Airtable API to bring in book data. Let’s explore how it’s built!
But first, the data
Choosing a data source
At the beginning of the year I signed up for the Currently Reading podcast’s Patreon, which—amonst other benefits—gives patrons access to an annual reading Google Sheet. With my 2024 reading in a structured data format, I started by figuring out whether Sheets had an API.
They do, but things were feeling a bit overly complex for a lil ol’ REST API, so I noped out of there pretty quickly. Airtable’s API, on the other hand, is quite awesome: not only is it easy to authenticate with, but they have also interactive API docs for any of your Airtable bases. I was able to explore bespoke documentation for exactly the fields in my database, and all of the example snippets returned actual values in my data. This made building with their API so much easier.
Backfilling data
For my 2024 data, I downloaded a CSV from that Google Sheet and uploaded it to my new Airtable base. For the rest of the 2020s, I exported a CSV from The Storygraph. You can find that function on Manage Account > Manage your data.
I then manually added some metadata to the pre-2024 books about author demographics and reading sources. I also uploaded book cover images to the base.
In the final output, I link to the books (mostly) on Bookshop.org, using a Bookshop ID field. I populated this field with the ISBN numbers that came in from The Storygraph, then ran the “Broken Link Checker” browser extension over the page to see which URLs I needed to fix (this was a big time saver, trust me).
Criteria
For my Reading page, I wanted to keep things simple:
- A list of books I’d read, in reverse chronological order, organized by year
- The book cover, a link, title, author, and rating for each book—along with special reasons for reading the book, if any
- Special treatments for my favorite books of the year, as well as books I decided not to finish
The most “interesting” piece of criteria for me was that Airtable doesn’t let you hotlink images from their API. Attachment URLs expire, so you have to download them somewhere else. This was my first time downloading and storing binary data from an API.
How it’s built
This walkthrough is an example of how you could use the Airtable API with Eleventy. I’m not the most confident with Node or JS promises, so it’s likely there’s a cleaner, better way to achieve this. Caveat emptor etc etc.
Storing secrets
First, I added to my .env file these secrets:
AIRTABLE_API_KEY=yourSecretKeyHere
AIRTABLE_BASE=yourBaseIdHere
I also added these to my Netlify environment variables, so that they’re used at build time at the dev platform this site.
Grabbing the data
Next, I created a data file in my project at /src/_data/reading/2020s.js, where /src/ is the root source directory for Eleventy. This file does a few things:
- Fetches records (the books) from my Books base, using the “All” view. You don’t have to name the view, but doing so means that the view’s sorts and filters are applied (i.e. you don’t have to do those transformations in code). Airtable’s data is paginated, and they very nicely have a built-in recursive function
fetchNextPage()to…fetch the next page, if one exists. - Reads the book’s
Year Readfield and pushes it to an array, if it’s not already there. This enables me to structure my books by year. - Then, creates a book object within that year by fetching several different fields from the record.
- Next, retrieves and downloads the book cover image, unless it’s already been stored in my code base. Because images are binary data, I needed to retrieve that data using the
pipe()function, and use a stream (fs.createWriteStream()) to write said data to a new file. - All of this data is returned in the Node module, and can now be used in my template files!
const Airtable = require('airtable');
const base = new Airtable({ apiKey: process.env.AIRTABLE_API_KEY }).base(process.env.AIRTABLE_BASE);
const https = require('https');
const fs = require('fs');
const imageDir = 'src/assets/images/is/reading/';
module.exports = () => {
return new Promise((resolve, reject) => {
const booksByYear = [];
// Specifying the Airtable view fetches records in the order they appear in that view
base('Books').select({ view: 'All' })
.eachPage(
function page(records, fetchNextPage) {
// This function (`page`) will get called for each page of records.
records.forEach((record) => {
const yearRead = record.get('Year Read');
// Add the year to the book list if it's not already there
if (!booksByYear.some(obj => obj.year === yearRead)) {
booksByYear.push({
year: yearRead,
books: []
});
}
// Add the book to the relevant year
booksByYear.find(obj => obj.year === yearRead).books.push({
title: record.get('Title'),
author: record.get('Author'),
bookshopId: record.get('Bookshop ID'),
specialUrl: record.get('Special URL'),
cover: record.get('Cover'),
DNF: record.get('DNF'),
fave: record.get('Fave'),
rating: record.get('Rating'),
starRating: record.get('Star Rating'),
reason: record.get('Reason for Reading'),
year: record.get('Year Read')
});
// Get cover image attachment
const cover = record.get('Cover')[0];
const coverFilename = cover.filename;
const coverUrl = cover.url;
const localCoverFile = imageDir + coverFilename;
// Download cover image, if it doesn't already exist
if (!fs.existsSync(localCoverFile)) {
const imageFile = fs.createWriteStream(localCoverFile);
https.get(coverUrl, function(response) {
response.pipe(imageFile);
// Close file stream
imageFile.on('finish', () => {
imageFile.close();
});
});
}
});
// To fetch the next page of records, call `fetchNextPage`.
// If there are more records, `page` will get called again.
// If there are no more records, `done` will get called.
fetchNextPage();
},
function done(err) {
if (err) {
reject(err)
} else {
resolve(booksByYear);
}
}
);
});
};
Rendering the data
I use Nunjucks for my layout template files. This portion of the page template:
- Creates a new page section and counts the number of finished vs DNFed (did not finish) books, for each year in the
reading.2020sarray. - Then loops through each book for that year.
{# Each reading year #}
{% for readingYear in reading.2020s %}
<section class="l-contain l-section">
<h2 class="u-center">{{ readingYear.year }}</h2>
{# Count number of books finished and DNFed #}
{% set finishedCounter = 0 %}
{% set DNFCounter = 0 %}
{% for book in readingYear.books %}
{% if book.DNF == true %}
{% set DNFCounter = DNFCounter + 1 %}
{% else %}
{% set finishedCounter = finishedCounter + 1 %}
{% endif %}
{% endfor %}
<p class="u-center | c-meta">Finished: {{ finishedCounter }}
{% if DNFCounter > 0 %}
| Did not finish: {{ DNFCounter }}
{% endif %}
</p>
{# Book list #}
<ul class="u-simple-list | c-is-items">
{% for book in readingYear.books %}
{% include "partials/book.njk" %}
{% endfor %}
</ul>
</section>
{% endfor %}
partials/book.njk goes a little something like this. I suppose the most interesting thing to call out is that the image dimensions are important for lazy loading.
<li class="c-is-item{% if book.DNF == true %} c-is-item--dnf{% endif%}{% if book.fave == true %} c-is-item--fave{% endif%}">
{% if book.fave == true %}<span class="u-all-caps | c-meta | c-is-item__tag">Fave</span>{% endif %}
{% if book.bookshopId %}
{% set bookUrl = "https://bookshop.org/a/15644/" + book.bookshopId %}
{% else %}
{% set bookUrl = book.specialUrl %}
{% endif %}
<a class="c-is-item__link" href="{{ bookUrl }}">
<img class="c-is-item__cover" src="{{ site.isImages }}/reading/{{ book.cover[0].filename }}" loading="lazy" width="{{ book.cover[0].width }}" height="{{ book.cover[0].height }}" alt="">
<span class="c-is-item__title">{{ book.title }}</span>
</a>
<span class="c-is-item__author">{{ book.author }}</span>
{% if book.DNF == true %}
<span class="c-meta | c-is-item__dnf">DNF</span>
{% else %}
<span class="c-is-item__rating">
<span class="u-vis-hidden">{{ book.rating }} stars</span>
<span aria-hidden="true">{{ book.starRating }}</span>
</span>
{% endif %}
{% if book.reason == 'Book club' or book.reason == 'SPL Book Bingo' %}
<span class="u-all-caps | c-meta | c-is-item__reason">{{ book.reason }}</span>
{% endif %}
</li>
And that’s it! I found this a super fun project to work on; best believe I’ve already got my Merlin bird observation data ported into Airtable. Three cheers for owning and playing with your own data!